Supported cluster architectures¶
The Ocean-stack structure is two-fold, an administration island and the managed islands.
The administration island storage and network must be sized to meet the needs of the islands it will manage. All the management data will be stored and accessed from there. Most of the cluster’s services will be hosted there.
The administration island nodes must be deployed and configured in triplets, for resiliency and quorum algorithm reasons.
It is strongly recommended that managed island should be connected to BGP-enabled switches that also supports L3 interfaces (Cisco Nexus 9k models does).
From a network point-of-view, an island is a separate entity. No broadcast nor multicast traffic is supported between islands.
Any OS is support on managed nodes as soon as it can use standard tools (PXE, iPXE, HTTP, DHCP, …) to boot or deploy.
This documentation will provide you an overview on how Ocean-stack is architectured and the required processes to install and operate the cluster. This document also contain a handbook that contains documentation about debugging, automating or any product-specific documentation that should be distributed with Ocean-Stack.
You should head to this documentation when you are:
Planning to install a cluster using Ocean-Stack
Installing the administration island of Ocean-Stack
Operating the administration island of Ocean-Stack
Management architecture¶
Network architecture¶
The reference Ocean Stack deployment scheme consists of a group of management servers that provides services for the entire cluster (designated as the top or worker management servers) and several server groups that provide services for a particular part (or islet) of the cluster (designated as proximity management servers).
Such islets may contain compute nodes, IP or LNET routers or anything else that forms the HPC cluster itself.
The network architecture is derived from this deployment scheme and follows the following rules:
Services provided by management servers may be bandwith-hungry. Network capacity planning must be taken into account. The network where those services are provided will be designated as the administration network.
Management servers or related equipment must be reachable through a trusted network (designated as the equipment network) isolated from user traffic.
The administration network may evolve over the cluster life time. Performance scalability and administration flexibility must be taken into account.
Each and every network brick must be redundant. Known single point of failure should be listed and kept in mind during the installation process.
In our reference deployment, the equipment network is as simple as possible. And to keep it dead simple, this network will be a single flat network consisting of stacked switches. All the management servers and equipments must be connected to this network.
The administration network consists of:
The core layer, where top and worker management servers are connected.
The aggregation layer, where proximity management servers are connected.
The (optional) acces layer, where end-nodes (like compute nodes) are connected. This last layer may be provided by the compute node drawers. It can also be merged with the aggregation layer if the number of end-nodes is limited.
To give a full picture, here is a concrete example. Imagine the following:
2 compute-node islets with 6 racks, each of them have an aggregated bandwitch of 40Gb/s. 240Gb/s aggregrated bandwith in total.
Each compute-node islet have 2 dedicated proximity management server. Connected with single 40Gb/s links.
3 top and 3 worker management servers with 40Gb/s links.
With such a cluster, the network architecture would be the following.
isletXX servers designates proximity management servers, and islets are numbered 10 and 20.
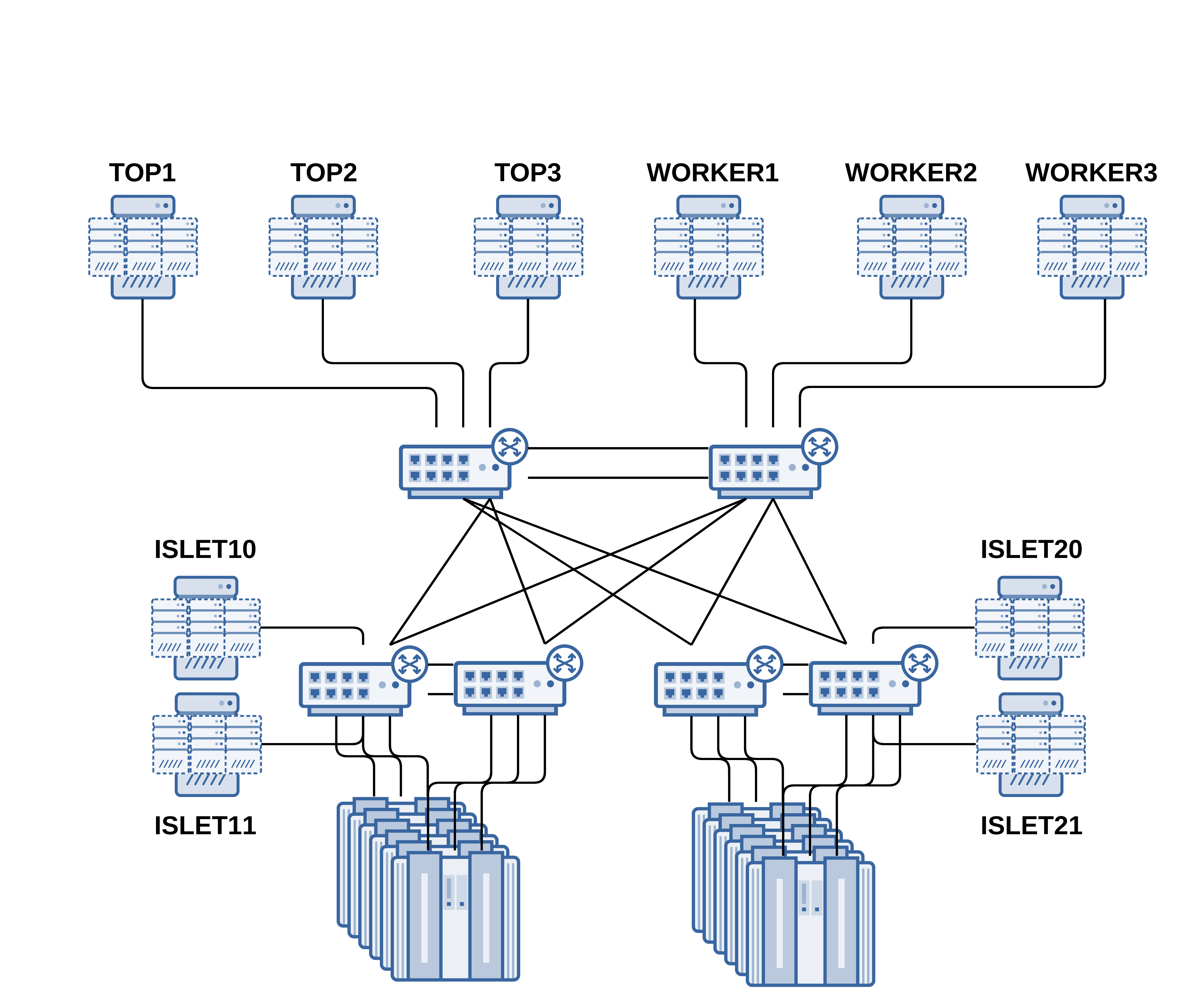
Here, the core layer is composed of two 40G/100G switches. The aggregation layer is composed of two 40G switches per islet and connected with four 40Gb/s links with the core layer. The acces layer is abstracted as it could be provided by the compute-node manufacturer and each rack is connected with four 10Gb/s links with the aggregation layer. Each proximity management server is connected to a different aggregation switch (the previous schema does not show this for clarity). top and worker management nodes are dispatched on both core switches.
With such a deployment, a service, like a shared FS, using all the top and worker management servers, can use up to 240Gb/s of network bandwidth. This resource is shared between all the compute-node islets, where each of them can use up to 160Gb/s of bandwidth.
On the other side, proximity management servers have 80Gb/s of per-islet dedicated bandwidth.
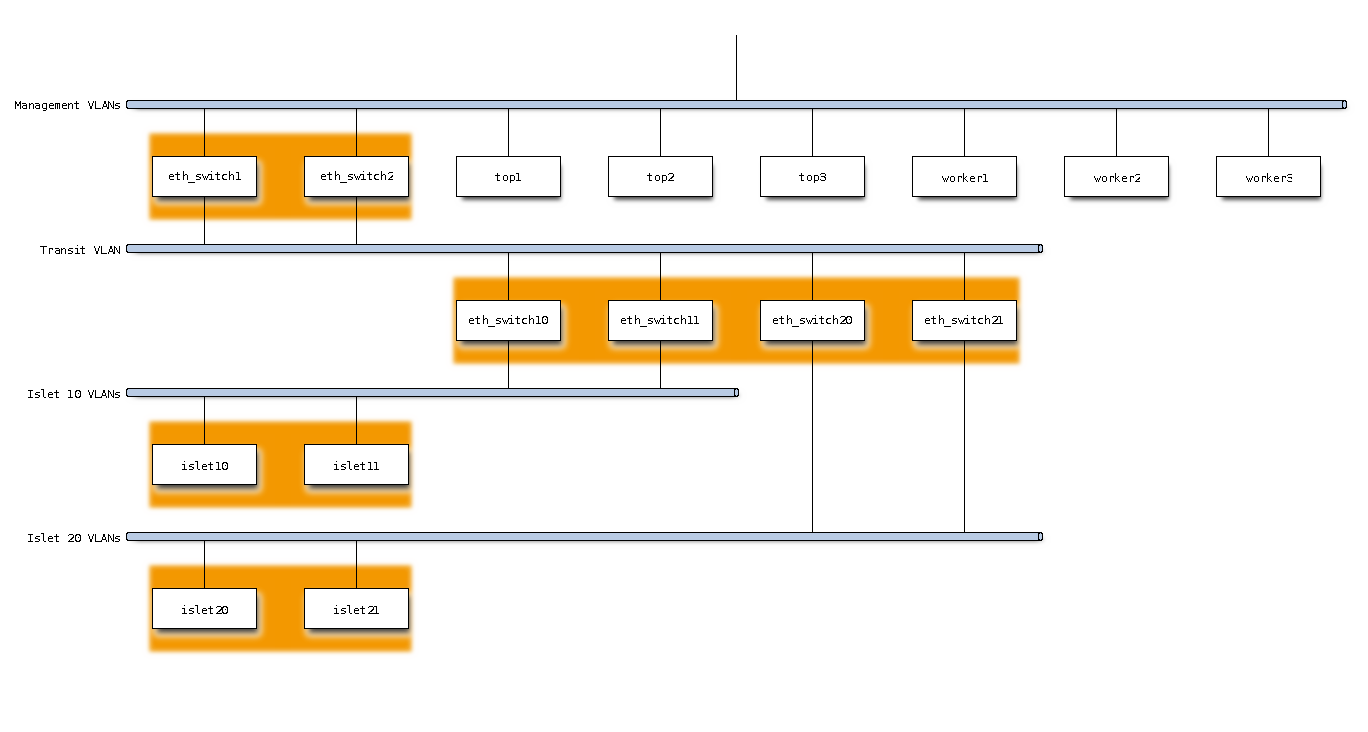
Each and every islet (and related proximity management server) forms a VLAN group where IP routing is achieved by the aggregation layer. The top and worker management servers are also grouped together.
IP routing between each group is either performed by the core and aggregation layers (2 hop routing) or dynamically routed by using all the links between the core and aggregation layers as a separate L2 network.
Such VLANs can be represented as follows:
Services architectures¶
Todo
Which, how and where services are hosted
The Ocean Stack project is based on a set of low level services and medium level services enabling to provide a set of high level services used to fulfill the requirements of cluster resources in terms of administration and management as well as the requirements of end-users in terms of services to access those resources on the cluster.
Low-level services bring a simple highly-available hyperconverged infrastructure enabling the provisioning of virtual machines on the set of available management nodes. This infrastructure is leverage to host the mid and high level services.
Low-level services include :
Glusterfs
Fleet
PCOCC
Mid-level services bring the required network flexibility to scale the management stack regarding the amount of resources to manage in the cluster.
Mid-level services include :
Named
HAProxy
Keepalived
High-level services provides all the traditional services commonly in production on production clusters to fulfill their management and usage requirements.
High-level services include:
HTTP
Puppet
LDAP
Rsyslog
Conman
Prometheus
Slurm
BMGR
External network IP routing
iSCSId
…
Services design details can be found in the following sections.